This is a simple story how we migrated a live production cluster with all its data into a new cluster, all without downtime.
Old cluster:
- 60 c4.4xlarge instances
- Cassandra 2.1.12, 256 vnodes per host
- Each instance had two 1500 GB GP2 EBS disks. This matches the c4.4xlarge EBS bandwidth quite well as max bandwidth for the instance is 250 MB/sec and the max EBS bandwidth is 160 MB/sec per disk.
- Total of 39 TiB of data with replication factor 3
New cluster:
- 72 i2.4xlarge instances, ephemeral SSDs
- Cassandra 2.2.7, no vnodes
- Initial import resulted in ~95 TiB of data.
- Initial compaction estimation was 21 days. Total compaction time around one week.
- 25 TiB of data after compaction.
Migration plan
We did a hot migration which we have done several times in the past. It’s based on the fact that all our operations are impotent in a way that we can do dual writes to both the old and the new cluster from our application. Once the dual writes have started we will know that all data from that point on will be stored on both the old and the new cluster. Then we initiate a BulkLoad operation from the old cluster to the new cluster, where we stream all SSTables into the new cluster instances.
When Cassandra does writes, it will store data with a timestamp field to the disk. When a field is updated a new record is created to a new SSTable which points to the same key, has the new value and most importantly has a newer timestamp. When Cassandra does reads it will read all entries, group them by the keys and then select only the newest entries for each key according to the timestamps.
We can leverage this behavior by BulkLoading all SSTables from the old cluster into the new cluster as any duplicated data will be handled automatically on the Cassandra read code path! In other words, it will not matter if we copy data from the old cluster to the new cluster which has already been written to the new cluster by the application doing dual writes. This fact makes migrations like this really easy and we can do these without any downtime.
So the steps are:
- Create new cluster and create keyspaces and table schemas into the new cluster.
- Modify application to write both the old and the new clusters. Keep the application reading from the old cluster.
- Run BulkLoader in every node in the old cluster so that it will read all SSTables from the instance in the old cluster and feed them into the new cluster.
- Wait that Cassandra compacts the loaded data.
- Do a incremental repair round so that all current data is incremental repaired once.
- Switch the application to do reads from the new cluster.
- Disable writes to the old cluster after you are sure that the new cluster works and can hold the load; you could still rollback to the previous cluster until this point.
- Destroy the old cluster.
Compaction phase
After the BulkLoader each instance in the new cluster will have a lot of SSTables which need to be compacted. This is especially the case if you streamed from every instance in the old cluster, so you should have three copies of every data (assuming ReplicationFactor 3) on every instance. This is normal, but this will take some time.
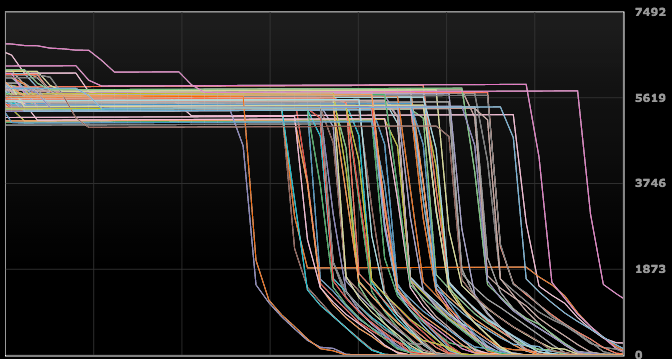
Initially each cluster instance had around 7000-8000 pending compactions, so the entire cluster had over half million pending compactions. Once streaming was completed the compaction started right away and in the end it took around one week. At the beginning the compaction speed felt slow: After one days worth of compaction I estimated that at that run rate it would take three weeks to compact everything. During the compaction each instance had one or two moments where only one giant compaction task was running for around one day and this seems normal. After this task was done then the Pending Compactions count dropped by several thousands and the remaining compactions went quite fast. If we look on the OpsCenter the PendingCompactions chart looked something like this in the end.
Because the bootstrap created a lot of small SSTables in L0 the Leveled Compaction switched to using STCS in L0, which resulted in a few big SSTables (from 20-50 GiB in size). This can be avoided by using the stcs_in_l0 flag in the table: ALTER TABLE … WITH compaction = {‘class’:’LeveledCompactionStrategy’, ‘stcs_in_l0’: false}; I did not use this and thus some of my compactions after repairs take longer than they might actually require.
Incremental repairs
We also switched to use Incremental Repairs (they are the new default in 2.2), so we ran couple of full repair cycles on the new cluster while it was still receiving only a partial production load. This gave us valuable information how we should tune streaming throughput and compaction threads in the new cluster to ensure values which don’t affect production. We ended up settling up with five compaction threads (out of 16 CPU cores).
Conclusions
Overall the migration went really well. Assuming you can make a code change which will do dual writes into two different cluster, this method is really nice if you need to migrate a cluster into a completely new one. Reasons for doing this kind of migration could be major revision number, changing deployment topology or perhaps changing machine type. This allows a nice way to rollback at any given moment, greatly reducing operational risks.