Asynchronous programming with Node.JS is easy after getting used to it but the single threaded model on how Node.JS works internally hides some critical issues. This post explains what everybody should understand on how the Node.JS event loop works and what kind of issues it can create, especially on high transactional volume applications.
What The Event Loop Is?
In the central of Node.JS process sits a relatively simple concept: an event loop. It can be thought as a never ending loop which waits for external events to happen and it then dispatches these events to application code by calling different functions which the node.js programmer created. If we think this really simple node.js program:
setTimeout(function printHello () {
console.log("Hello, World!");
}, 1000);
When this program is executed the setTimeout function is called immediately. It will register a timer into the event loop which will fire after one second. After the setTimeout call the program execution freezes: the node.js event loop will patiently wait until one second has elapsed and it then executes the printHello() function, which will print “Hello World!”. After this the event loop notices that there’s nothing else to be done (no events to be scheduled and no I/O operations underway) and it exists the program.
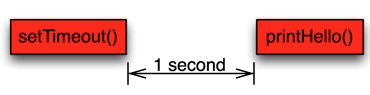
We can draw this sequence like this where time flows from left to right: The red boxes are user programmable functions. In between there’s the one second delay where the event loop sits waiting and until it eventually executes the printHello function.
Let’s have another example: a simple program which does a database lookup:
var redis = require('redis'), client = redis.createClient();
client.get("mykey", function printResponse(err, reply) {
console.log(reply);
});
If we look closely on what happens during the client.get call:
- client.get() is called by programmer
- the Redis client constructs a TCP message which asks the Redis server for the requested value.
- A TCP packet containing the request is sent to the Redis server. At this point the user program code execution yields and the Node.JS event loop will place a reminder that it needs to wait for the network packet where the Redis server response is.
- When the message is receivered from the network stack the event loop will call a function inside the Redis client with the message as the argument
- The Redis client does some internal processing and then calls our callback, the printResponse() function.
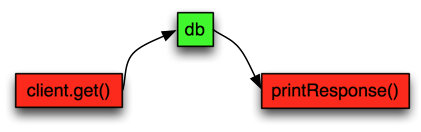
We can draw this sequence on a bit higher level like this: the red boxes are again user code and then the green box is a pending network operation. As the time flows from left to right the image represents the delay where the Node.JS process needs to wait for the database to respond over network.
Handling Concurrent Requests
Now when we have a bit of theory behind us lets discuss a bit more practical example: A simple Node.JS server receiving HTTP requests, doing a simple call to redis and then return the answer from redis to the http client.
var redis = require("redis"), client = redis.createClient();
var http = require('http');
function handler(req, res) {
redis.get('mykey', function redisReply(err, reply) {
res.end("Redis value: " + reply)
});
}
var server = http.createServer(handler);
server.listen(8080);
Let’s look again an image displaying this sequence. The white boxes represent incoming HTTP request from a client and the response back to that client.
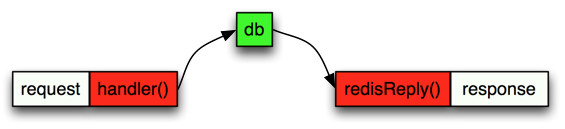
So pretty simple. The event loop receives the incoming http request and it calls the http handler immediately. Later it will also receive the network response from redis and immediately call the redisReply() function. Now lets examine a situation where the server receives little traffic, say a few request every few second:
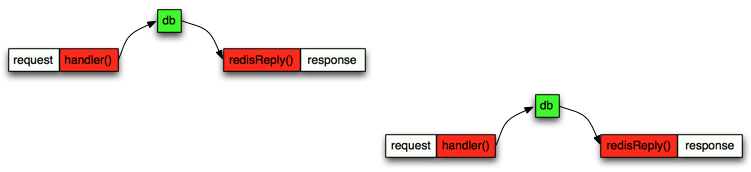
In this sequence diagram we have the first request on “first row” and then the second request later but drawn on “second row” to represent the fact that these are two different http request coming from two different clients. They are both executed by the same Node.JS process and thus inside the same event loop. This is the key thing: Each individual request can be imagined as its own flow of different javascript callbacks executed one after another but they are all actually executing in the same process. Again because Node.JS is single threaded then only one javascript function can be executing simultaneously.
Now The Problems Start To Accumulate
Now as we are familiar with the sequence diagrams and the notation I’ve used to draw how different requests are handled in a single timeline we can start going over different scenarios how the single threaded event loop creates different problems:
What happens if your server gets a lot of requests? Say 1000 requests per second? If each request to the redis server takes 2 milliseconds and as all other processing is minimal (we are just sending the redis reply straight to the client with a simple text message along it) the event loop timeline can look something like this:
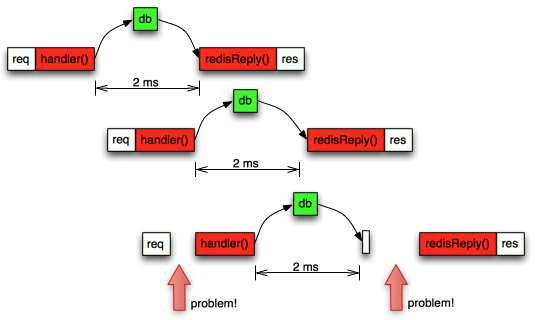
Now you can see that the 3rd request can’t start its handler() function right away because the handler() on the 2nd request was still executing. Later the redis reponse from the 3rd arrived after 2ms to the event loop, but the event loop was still busy executing the redisReply() function from the 2nd request. All this means that the total time from start to finish on the 3rd request will be slower and the overall performance of the server starts to degrade.
To understand the implications we need to measure the duration of each request from start to finish with code like this:
function handler(req, res) {
var start = new Date().getTime();
redis.get('mykey', function redisReply(err, reply) {
res.end("Redis value: " + reply);
var end = new Date().getTime();
console.log(end-start);
});
}
If we analyse all durations and then calculate how long an average request takes we might get something like 3ms. However an average is a really bad metric because it hides the worst user experience. A percentile is a measure used in statistics indicating the value below which a given percentage of observations in a group of observations fall. For example, the 20th percentile is the value (or score) below which 20 percent of the observations may be found. If we instead calculate median (which means 50%), 95% and 99% percentile values we can get much better understanding:
- Average: 3ms
- Median: 2ms
- 95 percentile: 10ms
- 99 percentile: 50ms
This shows the scary truth much better: for 1% of our users the request latency is 50 milliseconds, 16 times longer than average! If we draw this into graph we can see why this is also called a long tail: On the X-axis we have the latency and on the Y axis we have how many requests were completed in that particular time.
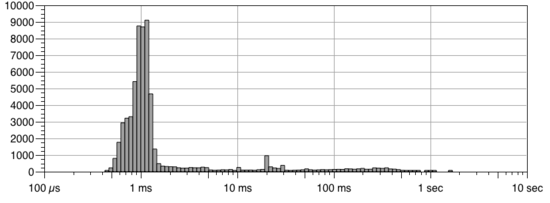
So the more requests per second our server servers, the more probability that a new request arrives before the previous is completed rises and thus the probability that the request is blocked due to other requests increases. In practice, with node.js when the server CPU usage grows over 60% then the 95% and 99% latencies start to increase quickly and thus we are forced to run the servers way below their maximum capacity if we want to keep our SLAs under control.
Problems With Different End Users
Let’s play with another scenario: Your website servers different users. Some users visit the site just few times a month, most visit once per day and then there are a small group of power users, visiting the site several times per hour. Lets say that when you process a request for a single user you need to fetch the history when the user visited your site during the past two weeks. You then iterate over the results to calculate whatever you wanted, so the code might look something like this:
function handleRequest(res, res) {
db.query("SELECT timestamp, action from HISTORY where uid = ?", [request.uid], function reply(err, res) {
for (var i = 0; i < res.length; i++) {
processAction(res[i]);
}
res.end("...");
})
}
A sequence diagram would look pretty simple:
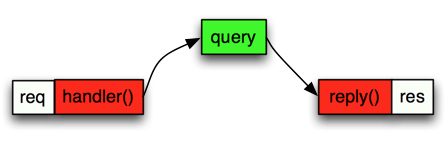
For the majority of the sites users this works really fast as a average user might visit your site 20 times within the past two weeks. Now what happens a heavy user hits your site which has visited the site 2000 times the past two weeks? The for loop needs to go over 2000 results instead of just a handful and this might take a while:
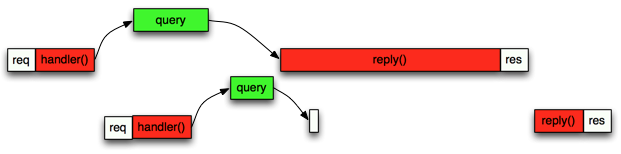
As we can see this immediately causes delays not only to the power user but all other users which had the back luck of browsing the site at the same time when a power user request was underway. We can mitigate this by using process.nextTick to process a few rows at a time and then yield. The code could look something like this:
var rows = ['a', 'b', 'c', 'd', 'e', 'f'];
function end() {
console.log("All done");
}
function next(rows, i) {
var row = rows[i];
console.log("item at " + i + " is " + row)
// do some processing
if (i > 0) {
process.nextTick(function() {
next(rows, i - 1);
});
} else {
end();
}
}
next(rows, rows.length - 1);
The functional code adds complexity but the time line looks now more favourable for long processing:
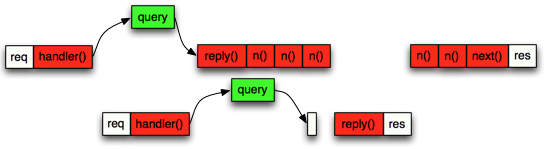
It’s also worth noting that if you try to fetch the entire history instead of just two weeks, you will end up with a system which performs quite well at the start but will gradually getting slower and slower.
Problems Measuring Internal Latencies
Lets say that during a single request your program needs to connect into a redis database and a mongodb database and that we want to measure how long each database call takes so that we can know if one of our databases is acting slowly. The code might look something like this (note that we are using the handy async package, you should check it out if you already haven’t):
function handler(req, res) {
var start = new Date().getTime();
async.series([
function queryRedis(cb) {
var rstart = new Date().getTime();
redis.get("somekey", function endRedis(err, res) {
var rend = new Date().getTime();
console.log("redis took:", (rend - rstart));
cb(null, res);
})
},
function queryMongodb(cb) {
var mstart = new Date().getTime();
mongo.query({_id:req.id}, function endMongo(err, res) {
var mend = new Date().getTime();
console.log("mongodb took:", (mend - mstart));
cb(null, res);
})
}
], function(err, results) {
var end = new Date().getTime();
res.end("entire request took: ", (end - start));
})
}
So now we track three different timers: one for each database call duration and a 3rd for the entire request. The problem with this kind of calculation is that they are depended that the event loop is not busy and that it can execute the endRedis and endMongo functions as soon as the network response has been received. If the process is instead busy we can’t any more measure how long the database query took because the end time measurement is delayed:
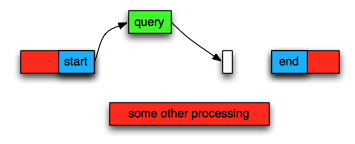
As we can see the time between start and end measurements were affected due to some other processing happening at the same time. In practice when you are affected by a busy event loop all your measurements like this will show highly elevated latencies and you can’t trust them to measure the actual external databases.
Measuring Event Loop Latency
Unfortunately there isn’t much visibility into the Node.JS event loop and we have to resort into some clever tricks. One pretty good way is to use a regularly scheduled timer: If we log start time, schedule a timer 200ms into the future (setTimeout()), log the time and then compare if the timer was fired more than 200 ms, we know that the event loop was somewhat busy around the 200ms mark when our own timer should have been executed:
var previous = null;
var profileEventLoop = function() {
var ts = new Date().getTime();
if (previous) {
console.log(ts - previous);
}
previous = ts;
setTimeout(profileEventLoop, 1000);
}
setImmediate(profileEventLoop);
On an idle process the profileEventLoop function should print times like 200-203 milliseconds. If the delays start to get over 20% longer than what the setTimeout was set then you know that the event loop starts to get too full.
Use Statsd / Graphite To Collect Measurements
I’ve used console.log to print out the measurement for the sake of simplicity but in reality you should use for example statsd + graphite combination. The idea is that you can send a single measurement with a simple function call in your code to statsd, which calculates multiple metrics on the received data every 10 seconds (default) and it then forwards the results to Graphite. Graphite can then used to draw different graphs and further analyse the collected metrics. For example actual source code could look something like this:
var SDC = require('statsd-client'), sdc = new SDC({host: 'statsd.example.com'});
function handler(req, res) {
sdc.increment("handler.requests")K
var start = new Date();
redis.get('mykey', function redisReply(err, reply) {
res.end("Redis value: " + reply);
sdc.timer("handler.timer", start);
});
}
Here we increment a counter handler.requests each time we get a new incoming request. This can be then used to see how many requests per second the server is doing during a day. In addition we measure how long the total request took to process. Here’s an example what the results might look when the increasing load starts to slow the system and the latency starts to spike up. The blue (mean) and green (median) latencies are pretty tolerable, but the 95% starts to increase a lot, thus 5% of our users get a lot slower responses.
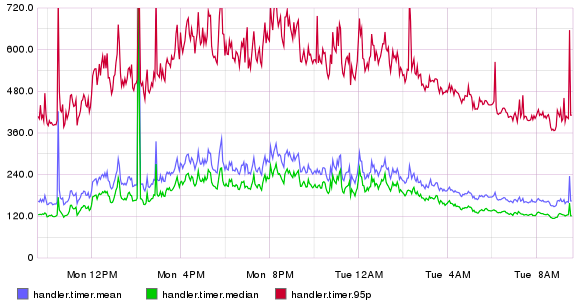
If we add the 99% percentile to the picture we see how bad the situation can really be:
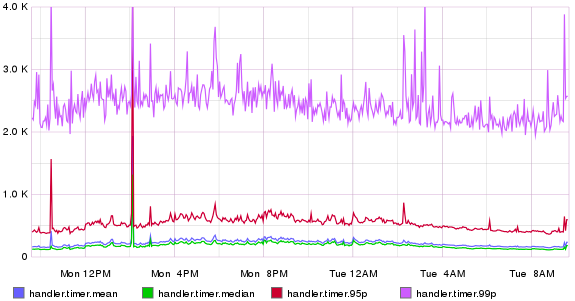
Conclusion
Node.JS is not an optimal platform to do complex request processing where different requests might contain different amount of data, especially if we want to guarantee some kind of Service Level Agreement (SLA) that the service must be fast enough. A lot of care must be taken so that a single asynchronous callback can’t do processing for too long and it might be viable to explore other languages which are not completely single threaded.